Abstract
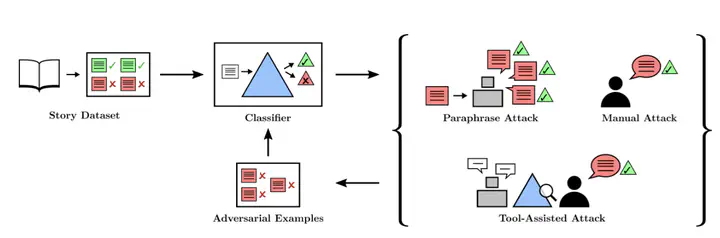
In the future, powerful AI systems may be deployed in high-stakes settings, where a single failure could be catastrophic. One technique for improving AI safety in high-stakes settings is adversarial training, which uses an adversary to generate examples to train on in order to achieve better worst-case performance. In this work, we used a safe language generation task (``avoid injuries’’) as a testbed for achieving high reliability through adversarial training. We created a series of adversarial training techniques – including a tool that assists human adversaries – to find and eliminate failures in a classifier that filters text completions suggested by a generator. In our task, we determined that we can set very conservative classifier thresholds without significantly impacting the quality of the filtered outputs. We found that adversarial training increased robustness to the adversarial attacks that we trained on – doubling the time for our contractors to find adversarial examples both with our tool (from 13 to 26 minutes) and without (from 20 to 44 minutes) – without affecting in-distribution performance. We hope to see further work in the high-stakes reliability setting, including more powerful tools for enhancing human adversaries and better ways to measure high levels of reliability, until we can confidently rule out the possibility of catastrophic deployment-time failures of powerful models.