Abstract
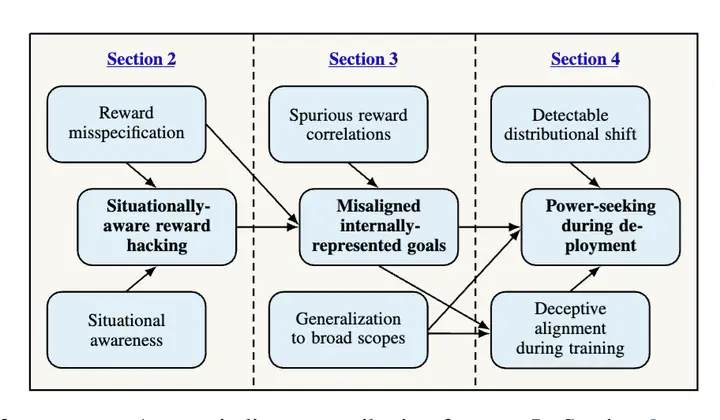
Within the coming decades, artificial general intelligence (AGI) may surpass human capabilities at a wide range of important tasks. We outline a case for expecting that, without substantial effort to prevent it, AGIs could learn to pursue goals which are very undesirable (in other words, misaligned) from a human perspective. We argue that AGIs trained in similar ways as today’s most capable models could learn to act deceptively to receive higher reward; learn internally-represented goals which generalize beyond their training distributions; and pursue those goals using power-seeking strategies. We outline how the deployment of misaligned AGIs might irreversibly undermine human control over the world, and briefly review research directions aimed at preventing these problems.