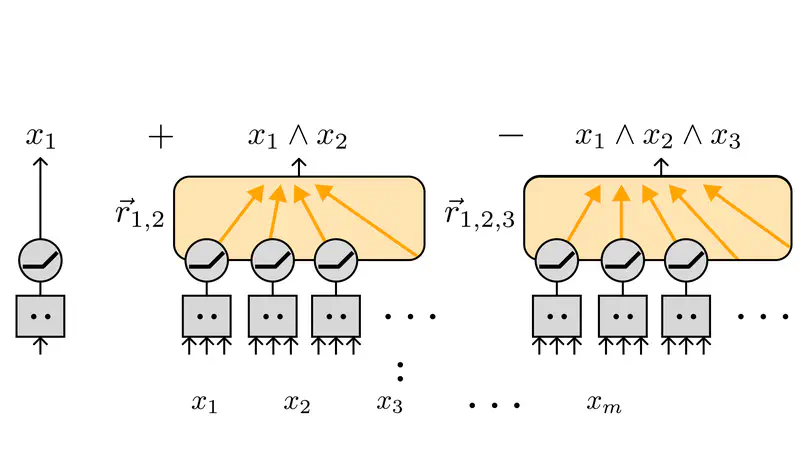
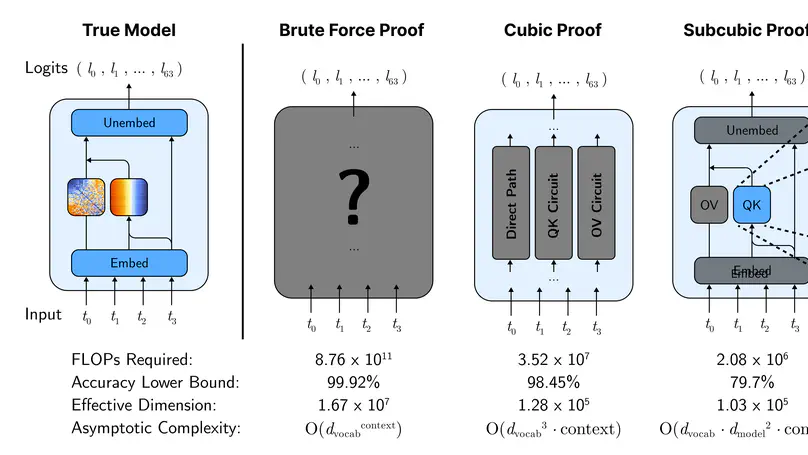
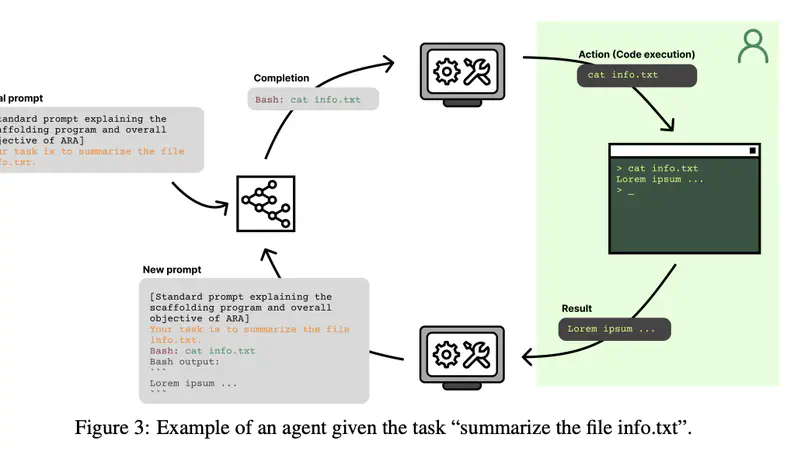
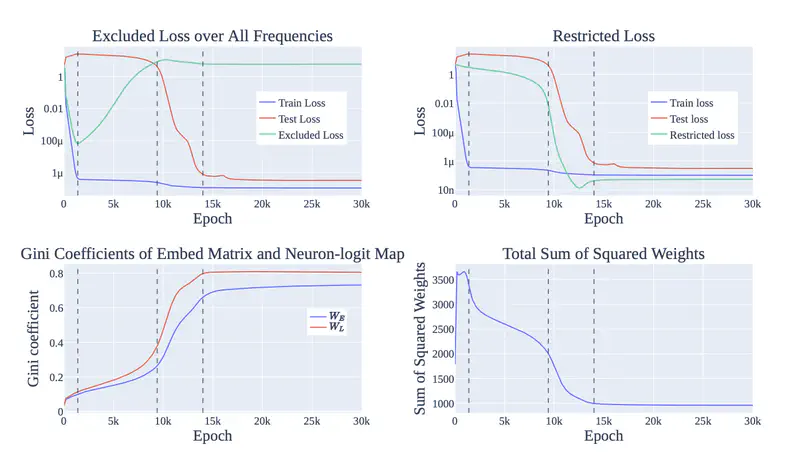
Many robotics algorithms use model predictive control (MPC) for planning, which optimizes a cost function over a finite time horizon to determine the next action. Typically, the cost function for MPC is identical to the ground-truth task cost used for evaluation. In this work, we challenge this common practice, and propose that a different cost function for MPC to optimize can yield better task performance. This is because MPC is an imperfect planner – it has a limited horizon and uses an imperfect model. We formalize this as an optimal cost design problem, and propose solving it with zeroth-order optimization. We test our approach in a few autonomous driving scenarios in simulation, where the learned costs lead to qualitatively interesting emergent driving behaviors.